問題背景
在金融機構和 CA 基礎設施中,Luna HSM 是密碼學金鑰的最終守護者。PKCS#11 API 提供完整的金鑰操作介面,但它有一個根本限制:PKCS#11 只是金鑰操作介面,不是監控介面。
當你需要知道以下問題時,PKCS#11 就幫不上忙了:
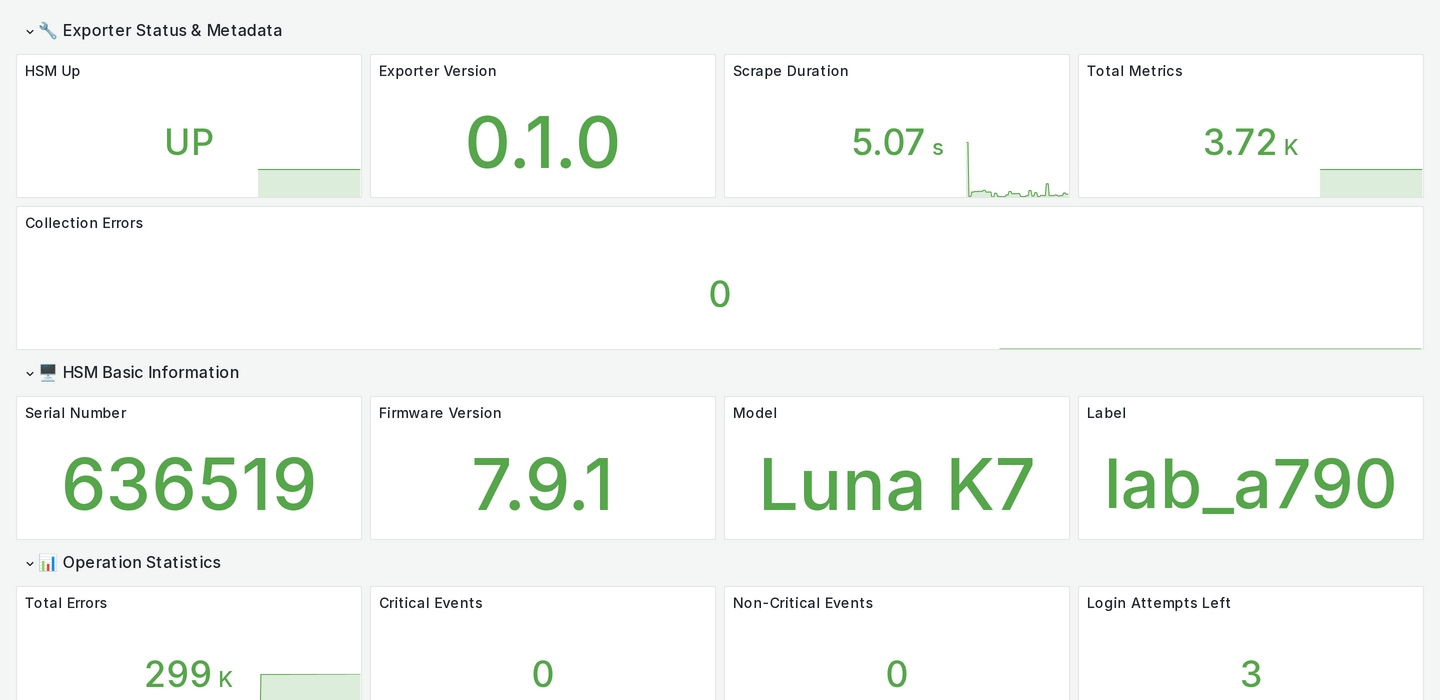
- HSM 硬體序號和韌體版本為何?
- 目前有多少 PKCS#11 Session 在使用(達到上限會無法建立新連線)?
- 分區儲存空間剩餘多少?
- Client 與 Partition 的分配關係是什麼?
- NTLS 憑證還有幾天到期?
這些問題的答案,需要透過另一個協定取得:SNMP(Simple Network Management Protocol)。
SNMPv3 的代價
Luna HSM 支援 SNMPv3 AuthPriv 模式(SHA 認證 + AES 加密),這是正確的安全配置。但 SNMP 收集並不便宜:
- 一次完整的設備狀態收集需要 60–90 秒(取決於網路延遲與分區數量)
- Prometheus 預設的 scrape 週期是 60 秒
這造成了一個結構性問題:生產者(SNMP 收集)比消費者(Prometheus scrape)慢。如果每次 scrape 都直接觸發 SNMP 收集,輕則 timeout,重則整個監控鏈斷掉。
整體架構
解決方案的核心思想:把 SNMP 收集從 scrape 路徑分離。
Exporter 啟動後,在背景持續輪詢 Luna HSM,收集的資料放入三層快取。Prometheus 每 60 秒來 scrape 時,直接從快取讀取,不觸發 SNMP 收集。
9 個 Collector
Exporter 以 Rust trait 物件實作 9 個 Collector,每個負責一組 MIB OID:
| Collector | 對應 MIB / 主要指標 | 估計 OID 數量 |
|---|---|---|
HsmStatsCollector | CHRYSALIS-UTSP-MIB::citsHsm — 操作請求、錯誤計數 | ~4 |
NtlsCollector | CHRYSALIS-UTSP-MIB::citsNtls — 連線客戶端數、憑證到期 | ~6 |
HsmTableCollector | SAFENET-HSM-MIB hsmTable — 韌體版本、序號 | ~20 |
LicenseTableCollector | SAFENET-HSM-MIB hsmLicenseTable — 授權功能狀態 | ~15 |
PolicyTableCollector | SAFENET-HSM-MIB hsmPolicyTable — HSM 政策設定 | ~500 |
PartitionPolicyCollector | SAFENET-HSM-MIB hsmPartitionPolicyTable — 分區政策 | ~3000 |
ClientRegistrationCollector | SAFENET-HSM-MIB hsmClientRegistrationTable | ~50 |
ClientSummaryCollector | Partition Table + Client-Partition Assignment(整合) | ~200 |
ApplianceCollector | SAFENET-APPLIANCE-MIB — 設備軟體版本 | ~5 |
PartitionPolicyCollector 因為每個分區都有完整的策略 OID 樹,在多分區環境下可達 3000+ OIDs,必須使用 SNMP GETBULK Walk 批次收集(每次最多回傳 50 行,大幅減少 round-trip 次數)。
ClientSummaryCollector 是設計上的一個優化點:它一次走 PartitionTable 和 ClientPartitionAssignment 兩張表,同時輸出 partition 原始 metrics 和 Client-Partition 聚合 metrics,避免重複走同一張慢表浪費網路 I/O。
三層快取設計
三層快取是這個系統的核心創新。讓我們看看它為什麼需要三層,而不是一層。
| 層級 | TTL | 設計理由 |
|---|---|---|
| Hot | 5 秒 | 防止同一個 60 秒 scrape 週期內重複觸發多次收集 |
| Warm | 55 秒 | 每次 SNMP 收集完成後重設;即使下輪收集超過 60 秒,Warm 依然有效,Prometheus scrape 不會看到空快取 |
| Cold | 無限 | SNMP 連線失敗時的最後保險,確保 scrape 永遠有資料可回傳 |
為什麼不用單層 TTL?
假設使用單層 60 秒 TTL:當 SNMP 收集恰好需要 62 秒,TTL 就會在收集完成前到期,下一次 scrape 看到空快取,需要等待新一輪收集完成。這個空窗期在生產環境中表現為 Grafana 的 No Data 時段。
三層設計透過 Warm 層和 Cold 層共同消除這個空窗:Warm(TTL 55 秒)先填補第 60–55 秒的缺口,之後 Cold(無 TTL)作為最後保險,確保 scrape 永遠有資料可回傳。
Rust FFI 包裝 Net-SNMP
Luna HSM 官方建議的 SNMP library 是 Net-SNMP(C library)。Rust 生態系沒有成熟的純 Rust SNMPv3 實作,因此我們用 FFI 包裝 Net-SNMP C library。
三層 Crate 結構
netsnmp-sys 是 bindgen 生成的 unsafe C bindings(不手動修改)
netsnmp 是安全的 Rust wrapper crate
rust-exporter 是使用 netsnmp 的應用層(lib 名稱:luna_snmp)
netsnmp-sys:bindgen 自動生成
build.rs 呼叫 bindgen 掃描 Net-SNMP 標頭檔,生成 unsafe Rust bindings:
// 由 bindgen 自動生成,不要手動修改
extern "C" {
pub fn snmp_open(
session: *mut snmp_session
) -> *mut snmp_session;
pub fn snmp_close(
session: *mut snmp_session
) -> ::std::os::raw::c_int;
}netsnmp:安全包裝層
Session struct 包裝 C session 指標,透過 RAII Drop 確保資源釋放。每輪收集開始前,manager 會呼叫 reconnect() 重新建立 session,防止長時間運行導致 UDP socket 狀態累積問題:
pub struct Session {
ss: *mut netsnmp_sys::netsnmp_session,
cfg: SessionConfig,
}
// SAFETY: libnetsnmp session 在單一 OS thread 上操作是 safe 的。
// Session 不實作 Sync,只實作 Send,確保同時只有一個 thread 存取。
unsafe impl Send for Session {}
impl Session {
pub fn open(cfg: &SessionConfig) -> Result<Self, SnmpError> { ... }
/// 關閉並重新建立 session(修復 UDP socket 累積問題)
pub fn reconnect(&mut self) -> Result<(), SnmpError> {
if !self.ss.is_null() {
unsafe { snmp_close(self.ss); }
self.ss = ptr::null_mut();
}
let ss = unsafe { open_v3_session(&self.cfg)? };
self.ss = ss;
Ok(())
}
pub fn bulk_walk(&self, root_oid: &str) -> Result<Vec<OidValue>, SnmpError> { ... }
}
impl Drop for Session {
fn drop(&mut self) {
// SNMP session 在 Rust 物件銷毀時自動釋放
if !self.ss.is_null() {
unsafe { netsnmp_sys::snmp_close(self.ss); }
}
}
}CollectorManager:Panic Recovery 設計
生產環境中,FFI 呼叫偶爾可能因 C library 內部狀態異常而 panic。Manager 使用 catch_unwind 包裝收集迴圈,自動重啟而不是靜默停止:
pub fn start(cfg: SessionConfig, cache: Cache, interval: Duration) -> Self {
let handle = thread::spawn(move || {
loop {
// Panic recovery:若 FFI 呼叫意外 panic,等 5s 後自動重啟
let result = std::panic::catch_unwind(
std::panic::AssertUnwindSafe(|| {
collection_loop(cfg.clone(), cache.clone(), interval);
})
);
if let Err(e) = result {
eprintln!("[manager] panicked: {e:?}; restarting in 5s");
thread::sleep(Duration::from_secs(5));
}
}
});
CollectorManager { _handle: handle }
}Luna 特有的 OID 字串解碼
Luna 的 client 名稱使用非標準編碼:OID 值不是直接的 UTF-8 字串,而是 [length, char1, char2, ...] 格式。
// oid/decoder.rs
pub fn decode_oid_string(parts: &[&str]) -> String {
if parts.is_empty() {
return String::new();
}
let length: usize = match parts[0].parse() {
Ok(n) => n,
Err(_) => return String::new(),
};
if parts.len() < length + 1 {
return String::new();
}
let mut result = String::with_capacity(length);
for s in &parts[1..=length] {
match s.parse::<u8>() {
Ok(b) if b.is_ascii_graphic() || b == b' ' => result.push(b as char),
_ => return String::new(), // 非可印字元視為解碼失敗
}
}
result
}沒有這個解碼步驟,ClientRegistrationCollector 和 ClientSummaryCollector 收到的客戶端名稱會是亂碼。這是 Luna HSM 文件中不太顯眼的細節,Python 版本當初也遇到過這個問題。
/health 端點:三狀態健康模型
Rust exporter 的健康端點根據快取年齡回傳三種狀態:
| 狀態 | 條件 | HTTP code |
|---|---|---|
initializing | 從未成功收集(age < 0) | 200 |
healthy | 快取資料在正常範圍內 | 200 |
stale | 超過 2 倍 collection interval 未更新 | 503 |
GET /health
→ {"status":"healthy","cache_age_seconds":42.3}
GET /health(資料過舊)
→ HTTP 503
→ {"status":"stale","cache_age_seconds":180.5}stale 回傳 503 讓 Kubernetes liveness probe 或外部監控能自動偵測 exporter 失能,而不只是靜默地提供陳舊資料。
Python / Go / Rust 三語言比較
漸進式重寫的歷史
這個專案的演進是典型的「漸進式重寫」:
- Python:快速驗證概念,2 週內有 working prototype,但 GIL 限制並行能力,型別問題讓維護困難
- Go:改善並發模型,靜態型別讓重構更安全,但在 FFI boundary 出現 session lifetime bug
- Rust:borrow checker 從根本解決 session lifetime 問題,且效能顯著提升
技術特性比較
| 項目 | Python | Go | Rust |
|---|---|---|---|
| SNMP 函式庫 | pysnmp / easysnmp | gosnmp | netsnmp-sys(FFI) |
| 型別系統 | 動態型別 | 靜態型別 | 靜態型別 + borrow checker |
| 錯誤處理 | Exception | error return | Result<T, E> |
| 並行模型 | asyncio(受 GIL 限制) | goroutine | 同步 + OS thread |
| HTTP server | Flask/aiohttp | net/http | tiny_http(無 async runtime) |
| 二進位大小 | —(需 runtime) | ~8 MB | ~4 MB(strip 後) |
| 部署複雜度 | 高(Python 環境管理) | 低(單一 binary) | 低(單一 binary) |
| 開發迭代速度 | 最快 | 快 | 較慢(編譯器嚴格) |
| FFI 安全性 | 無靜態保證 | 部分保證 | borrow checker 強制 |
Benchmark:資料處理層
以下是各項關鍵操作的實測效能數據(合成資料,不含 SNMP 網路 I/O):
| Benchmark | 說明 | Python | Go | Rust |
|---|---|---|---|---|
| OID 字串解碼 | ['3','75','77','83'] → 'KMS' | 290 ns | 23.0 ns(12.6x) | 14.4 ns(20.2x) |
| Client-Partition OID 解析 | 完整 OID → (client, serial) | 1.66 µs | 311 ns(5.3x) | 223 ns(7.4x) |
| Partition 序號提取 | OID instance 提取 | 1.07 µs | 245 ns(4.4x) | 206 ns(5.2x) |
| OID → metric 名稱查表 | 7 個 OID HashMap 查詢 | 1.96 µs | 74.5 ns(26.3x) | 143 ns(13.7x) |
| SNMP 值類型格式化 | 7 種 SNMP vtype | 2.70 µs | 498 ns(5.4x) | 115.5 ns(23.3x) |
| Enum 映射(NTLS 狀態) | 6 個值查表 | 869 ns | 928 ns(慢) | 83.3 ns(10.4x) |
| 1000 行端對端處理 | 完整 parse pipeline | — | 603.5 µs | 43.6 µs(13.8x) |
- Rust 平均加速比(相對 Python,資料處理層):~13.4x
- Go 平均加速比(相對 Python,資料處理層):~9.2x
- OID 表格查表(HashMap)Go 比 Rust 快(26.3x vs 13.7x)——HashMap 實作差異所致
- 端對端處理 1000 行:Rust 43.6 µs vs Go 603.5 µs(13.8x)
注意: 這是純資料處理層的 benchmark,端對端收集時間主要受 SNMP 網路延遲決定,三種語言在這一層差距不大(~100–130 ms/request)。
為什麼最終選 Rust,不是 Go?
效能不是決定性因素。真正的問題是 session lifetime bug:
Go 版本在高並行負載下,goroutine 有機率在 session 被 snmp_close 後繼續使用已釋放的 C 指標,導致不定時的 segfault。這個 bug 難以在測試環境重現,更難以系統性地修復。
Rust 的 borrow checker 在編譯時就防止了這類問題:持有 Session 引用的程式碼,編譯器可以靜態保證其生命週期不超過 Session 物件本身。這個 bug 不是被修復,而是無法被寫出。
部署:Container 化
Rust exporter 支援 Podman/Docker 容器部署,提供 podman-compose.yaml 供多 HSM 場景使用:
services:
snmp-exporter-hsm-01:
image: luna-rust-snmp-exporter:latest
ports:
- "9116:9116" # HSM-01 exporter
environment:
- SNMP_TARGET=${HSM_01_IP}
- SNMP_AUTH_PASSWORD=${SNMP_AUTH_PASSWORD}
- SNMP_PRIV_PASSWORD=${SNMP_PRIV_PASSWORD}
- COLLECTION_INTERVAL_SECS=60
snmp-exporter-hsm-02:
image: luna-rust-snmp-exporter:latest
ports:
- "9117:9116" # HSM-02 exporter(不同 host port)
environment:
- SNMP_TARGET=${HSM_02_IP}
...每個 HSM 對應一個 container 實例,各自維護獨立的 SNMP session 和三層快取。Grafana 可透過 job label 區分不同 HSM 的 metrics。
結語
三層快取是「生產者比消費者慢」這個通用問題的一個解法,適用於任何需要解耦收集與讀取週期的場景,不限於 SNMP 監控。
Rust FFI 的學習曲線確實陡峭,但在 C library boundary 的正確性保證上,borrow checker 提供了其他語言無法比擬的靜態保證。如果你的系統有 unsafe C 互動,Rust 不只是效能工具,更是正確性工具。
Panic recovery、session reconnect、三狀態健康端點——這些看起來像是「防禦性過設計」的細節,在生產環境跑了幾個月後,會感謝當初把它們加上去。
如果你也在監控 Luna HSM 或其他 SNMP-only 設備,歡迎透過聯絡頁面交流。