
問題背景
Western Blot(WB)是蛋白質表達研究最基礎的實驗技術之一,配合免疫組織化學染色(IHC)、免疫螢光(IF)及流式細胞術(FC)等應用,抗體試劑的正確選擇是決定實驗成敗的關鍵。
然而,現行的抗體選購流程存在嚴重痛點:
- 資訊碎片化:各廠商驗證資料、文獻引用、客戶評價分散於不同平台,難以橫向比較
- 選擇耗時:單一目標蛋白可能有數十乃至數百種候選抗體,手動篩選往往耗費數小時
- 缺乏客觀標準:傳統選擇依賴個人經驗,主觀性高、可重現性低
- 批次實驗困境:蛋白質體學研究需同時篩選數十種蛋白的抗體,人工作業幾乎不可行
- 驗證圖片品質難以評估:WB 條帶的特異性、背景雜訊、分子量符合程度需要專業判讀
核心洞察
以 Western Blot 為例,研究人員需確認抗體在目標物種的對應組織或細胞系中,於正確分子量位置產生清晰且特異的條帶,同時無或極少非特異性訊號。這樣的判斷涉及多個維度的資訊整合——正是 AI 系統的強項所在。
實際場景:一位研究人員在篩選 UVRAG 蛋白抗體時,需比對其在 HeLa 細胞株(Human)、LO2 肝細胞、小鼠肝臟與大鼠腦等多物種樣本的 WB 表現,確認約 90 kDa 處的目標條帶強度與特異性。此類多物種、多組織的交叉比對,在系統化工具輔助下才能真正高效執行。
系統架構總覽
整個系統採用模組化設計,最核心的差異化在於規則引擎 + AI 混合評分架構:

技術棧
| 層級 | 技術選型 | 說明 |
|---|---|---|
| Web 前端 | HTML5 + Tailwind CSS + Vanilla JS | 響應式介面、互動式跳窗元件 |
| Web 後端 | Flask 2.3+ + CORS | RESTful API 設計 |
| AI 框架 | LangChain + VLM(LLaVA-Med / Qwen2-VL) | LLM 語意理解 + 視覺分析 |
| ORM | SQLAlchemy 2.0+ | 資料庫抽象層 |
| 資料庫 | SQLite(WAL mode) | 零配置、支援並發讀取 |
| 爬蟲 | BeautifulSoup4 + Requests | 多執行緒平行爬取 |
| 外部 API | NCBI PubMed | 文獻引用資訊 |
核心設計:三層混合評分架構
市面現有的廠商官網搜尋功能僅能依條件過濾,無排序評分。本系統的核心差異在於:跨廠商資料整合 × 規則 + AI 混合評分 × VLM 驗證圖片分析 × 批次處理能力,四者合一。
第一層:規則引擎(Rule-based)
依物種匹配、應用匹配、驗證數量等量化規則計算基礎分數,確保評分的可解釋性:
class FlexibleScoringEngine:
"""可配置的評分引擎——權重儲存在資料庫中,可動態調整"""
def calculate_score(self, antibody, requirement):
score = 0.0
score += weights['base_score'] # 基礎分 10
score += len(images) * 5 # 驗證圖片:每張 +5
score += matched_apps * 15 # 應用匹配:每項 +15
score += matched_species * 10 # 物種匹配:每項 +10
score += 20 if host_match else 0 # 宿主匹配 +20
score += 15 if monoclonal else 0 # 單克隆加分 +15
score += dilution_bonus # 高稀釋倍率 +5~10
return score| 評分因子 | 權重 | 設計理由 |
|---|---|---|
| 應用匹配 | 15/項 | 最重要——應用不匹配的抗體毫無用處 |
| 宿主匹配 | 20 | 影響二抗選擇和實驗設計 |
| 單克隆加分 | 15 | 特異性高、批次穩定性好 |
| 物種匹配 | 10/項 | 基本門檻,篩選已處理大部分不匹配 |
| 驗證圖片 | 5/張 | 有實驗數據支持的產品更可靠 |
| 稀釋倍率 | 5–10 | 高倍率 = 省試劑、降成本 |
第二層:VLM 視覺分析
這是本系統最大的技術突破——引入 LLaVA-Med / Qwen2-VL 等醫學圖像專用視覺語言模型,直接「看懂」WB 驗證圖片:
傳統工具無法評估驗證圖片品質,而 VLM 能自動判斷:
- 條帶是否出現在正確的分子量位置
- 條帶清晰度是否達標
- 是否存在非特異性雜訊
- 不同物種、組織樣本的表現差異
第三層:LLM 文字分析
透過 LangChain 整合大型語言模型,分析抗體產品描述、驗證說明文字,進行語意層面的品質評估。三層評分最終以加權方式整合,輸出推薦排序。
四步驟智能篩選流程
系統提供完整的端到端(End-to-End)推薦流程:
Step 1:目標蛋白識別
支援蛋白名稱、基因 ID(Gene ID)、UniProt 編號及別名等多種輸入,自動解析並確認目標蛋白身份。內建常用蛋白快捷選單(P53、GAPDH、β-actin、BRCA1 等)。
Step 2:樣本來源與應用篩選
提供 Human、Mouse、Rat 等 10 種物種選項,以及 WB、IHC、IF、FC、ELISA 等實驗應用的多選篩選,支援交叉條件組合。
Step 3:驗證數據評估
自動整合三類驗證資訊:
- 原廠驗證:廠商提供的 WB / IHC / IF 驗證圖片,支援跳窗放大檢視
- 文獻引用:整合 NCBI PubMed 資料,顯示引用文獻及連結
- 客戶審查:Customer Review 記錄,來自實際使用者的實驗回饋
VLM 在此階段介入,對驗證圖片進行自動品質評估。
Step 4:智能推薦輸出
依綜合評分排序,呈現最佳候選抗體。每個推薦結果附帶詳細推薦理由——說明評分依據(例如:「此抗體在 Human WB 有 12 篇文獻引用,3 張原廠驗證圖片,條帶清晰度高」),而非黑盒子輸出。
推薦流程:資料庫優先策略
推薦引擎採用資料庫優先、爬蟲補充的策略,兼顧回應速度與資料新鮮度:
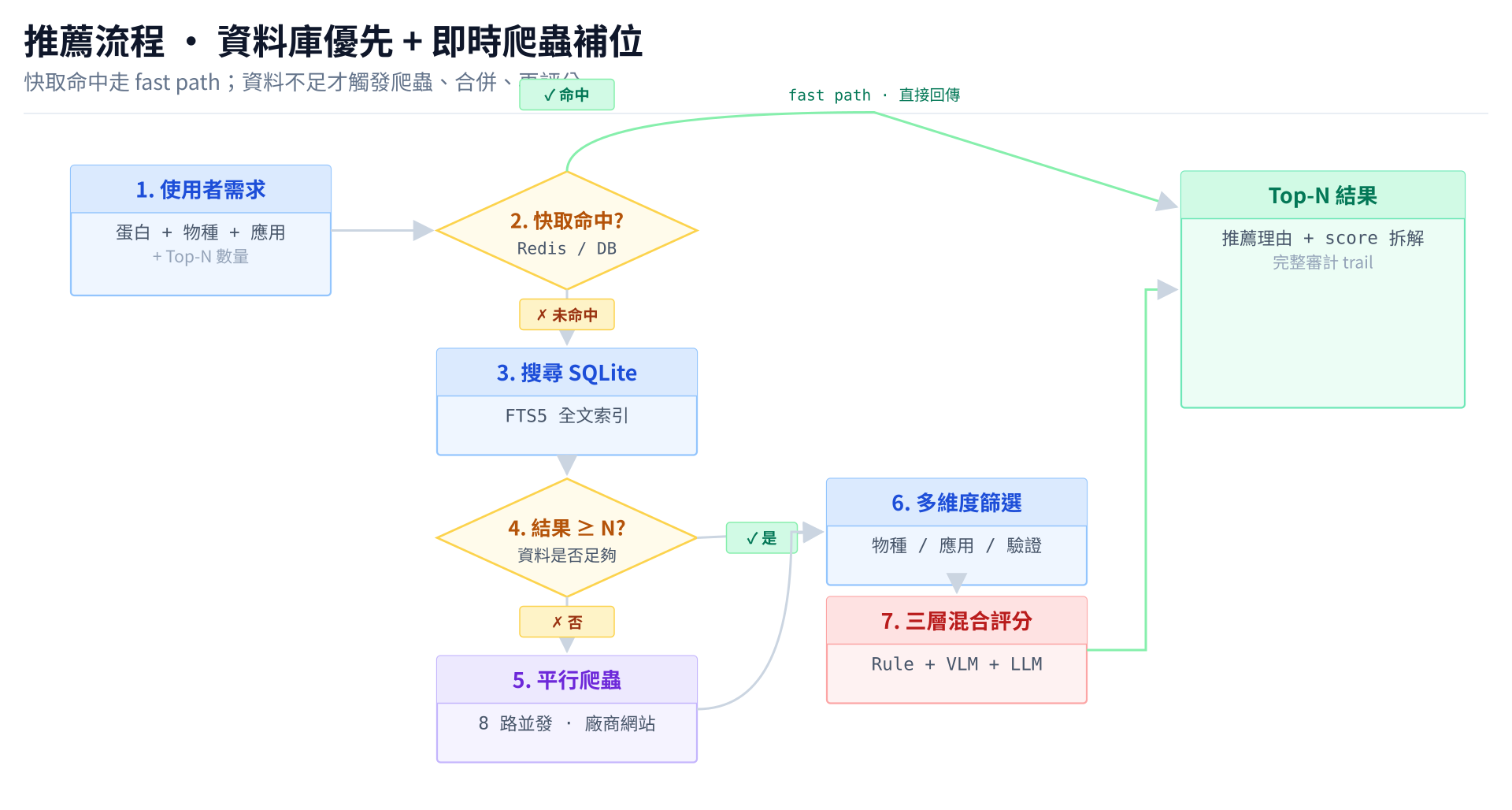
- 首次查詢:觸發爬蟲,結果存入 SQLite
- 重複查詢:直接從資料庫取資料,毫秒級回應
- 24 小時 TTL:快取自動過期,確保資料不會太舊
背景任務與即時進度
Web 介面不能讓使用者等待 30 秒的爬蟲結果。解決方案:先回傳資料庫結果,爬蟲放到背景執行,前端即時顯示處理進度狀態。
背景任務系統支援:
- 即時進度顯示:前端 Processing Status 元件,使用者可追蹤處理狀態
- 任務狀態追蹤:pending → running → completed / failed
- 結果快取:完成的任務結果保留在記憶體中,24 小時過期
- 取消機制:使用者可以中途取消不需要的任務,釋放資源
批次處理:蛋白質體學的核心需求
蛋白質體學(Proteomics)研究需同時篩選數十種蛋白的抗體。批次處理介面支援一次輸入多個目標蛋白,系統平行處理並漸進式顯示結果——每完成一個蛋白的搜尋,前端立即呈現該蛋白的推薦結果,不需等所有蛋白都處理完畢。
{
"proteins": ["P53", "GAPDH", "β-actin", "BRCA1", "UVRAG"],
"species": ["Human", "Mouse"],
"applications": ["WB", "IHC"],
"max_results_per_protein": 5
}結果呈現:透明化推薦
搜尋結果以統一格式的卡片呈現,每張卡片提供完整的決策資訊:
- 推薦排名與評分:綜合三層評分的最終分數
- 產品基本資訊:名稱、目錄編號、宿主、克隆類型
- 生物特性:支援的應用類型、物種反應性、稀釋倍率
- 驗證圖片輪播:WB / IHC / IF 驗證圖片,支援跳窗放大檢視
- 文獻引用:PubMed 文獻列表及 NCBI 連結(跳窗顯示)
- 客戶審查:Customer Review 記錄(跳窗顯示)
- 推薦理由:明確說明評分依據,非黑盒輸出
平行爬蟲設計
爬蟲是系統中最慢的環節。我們使用 ThreadPoolExecutor 實現多頁平行爬取:
class AntibodyDataCrawler:
def search_antibodies_parallel(self, protein, max_pages=3):
with ThreadPoolExecutor(max_workers=5) as executor:
futures = {
executor.submit(self._fetch_page, protein, page): page
for page in range(1, max_pages + 1)
}
for future in as_completed(futures):
products.extend(future.result())
return products關鍵設計決策:
- 每個執行緒獨立 Session:避免 cookie 和連線狀態衝突
- 最多 5 個 Worker:在效率與對目標網站的友善度之間取得平衡
- 逾時處理:單頁爬取超過 30 秒自動放棄,不影響其他頁面
- 產品詳細頁爬取:從列表頁深入單一產品頁,取得驗證圖片、稀釋倍率等詳細資訊
資料庫設計
SQLite 搭配 SQLAlchemy ORM,簡單但足夠應付 POC 規模:
-- 核心表:抗體產品
CREATE TABLE antibody_products (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
catalog_number TEXT,
host TEXT,
applications TEXT, -- JSON array
species_reactivity TEXT, -- JSON array
validation_images TEXT, -- JSON array
dilutions TEXT, -- JSON object
estimated_citations INTEGER,
data_source_id INTEGER,
updated_at TIMESTAMP,
UNIQUE(catalog_number, data_source_id)
);SQLite 的 WAL(Write-Ahead Logging)模式讓讀寫可以並行,配合 busy_timeout=30000、cache_size=10000,足以應對中等負載。
產品迭代規劃
| 版本 | 時程 | 重點 |
|---|---|---|
| v1.x | 短期 | 擴充支援的抗體廠商數量;新增 ELISA、ChIP、Co-IP 應用;優化 VLM 圖片分析精準度(目標 F1-Score ≥ 0.90) |
| v2.x | 中期 | 使用者實驗記錄功能,根據歷史 WB 結果進行個人化推薦;支援條帶強度(Band Density)定量數據回饋 |
| v3.x | 長期 | 結合基因表現資料(RNA-seq)與蛋白質互作網路(PPI),提供上下游靶點的抗體套組推薦;整合 LIMS 實驗室管理系統 |
經驗與反思
規則 + AI 的平衡
純規則引擎可解釋但缺乏深度判斷力;純 AI 模型強大但黑盒。混合架構讓我們在透明性與智能性之間取得平衡——規則層確保基本邏輯正確,VLM 層提供人類難以規模化的圖片品質判斷。
VLM 在生物醫學的潛力
將 LLaVA-Med 等醫學圖像專用 VLM 引入抗體推薦,是本系統最大的技術突破。VLM 能直接「看懂」WB 驗證圖片,從根本上改變了抗體品質評估的方式——這個能力不僅適用於抗體推薦,未來可擴展到任何需要圖片品質判讀的生物醫學場景。
爬蟲的脆弱性
Web scraping 本質上依賴於目標網站的 HTML 結構。更穩健的做法是使用官方 API(如果有的話)或建立多資料源的 fallback 機制。系統架構已為多廠商整合預留擴充點。
推薦理由的重要性
研究人員不接受黑盒推薦。每個推薦結果都必須附帶清晰的評分依據,讓使用者能理解並信任系統的判斷。這不只是 UX 問題,而是科學研究對可重現性(Reproducibility)的基本要求。
產業應用潛力
| 領域 | 效益 |
|---|---|
| 學術研究 | 抗體選擇週期從數小時壓縮至數分鐘;VLM 圖片分析從人工 5 分鐘降至約 10 秒 |
| 蛋白質體學 | 批次查詢使大規模抗體篩選成為可能 |
| 生技製藥 | 加速靶點驗證,標準化選用流程提升研究重現性 |
| 抗體代理商 | 協助客戶快速定位適合產品 |
全球研究用抗體市場規模逾 30 億美元,潛在的商業模式包括 SaaS 訂閱、廠商合作、機構授權等方向。
小結
智能抗體推薦系統的核心突破在於將 VLM 視覺語言模型引入抗體推薦流程。系統不僅能評估數量性指標(文獻引用、驗證圖片張數),更能透過醫學圖像專用 VLM 直接分析 WB 驗證圖片的品質——判斷條帶位置、清晰度、非特異性雜訊。
這種規則引擎與 AI 模型的協同設計,帶來精準的推薦輸出,同時確保推薦理由的透明性與可解釋性。對於「領域知識 + AI + 資料整合」型的應用場景,這套混合評分架構是一個值得參考的設計模式。